전에 살펴본 이웃의 개수가 1일 경우에(n_neighbors = 1), 테스트 데이터가 어떤 클래스에 속할지에 대한 예측은 단순히 테스트 데이터에 가장 가까운 훈련 데이터의 출력을 기준으로 예측하는 것이었다.(https://honeyteacs.tistory.com/12?category=688750)
하지만 이웃의 개수가 1이 아닌 여러개일(n_neighbors = k) 경우에는 각 이웃이 속하는 클래스를 따져본 후, 가장 많은 이웃이 속하는 클래스를 선택하는 방식으로 클래스를 예측하게 된다.


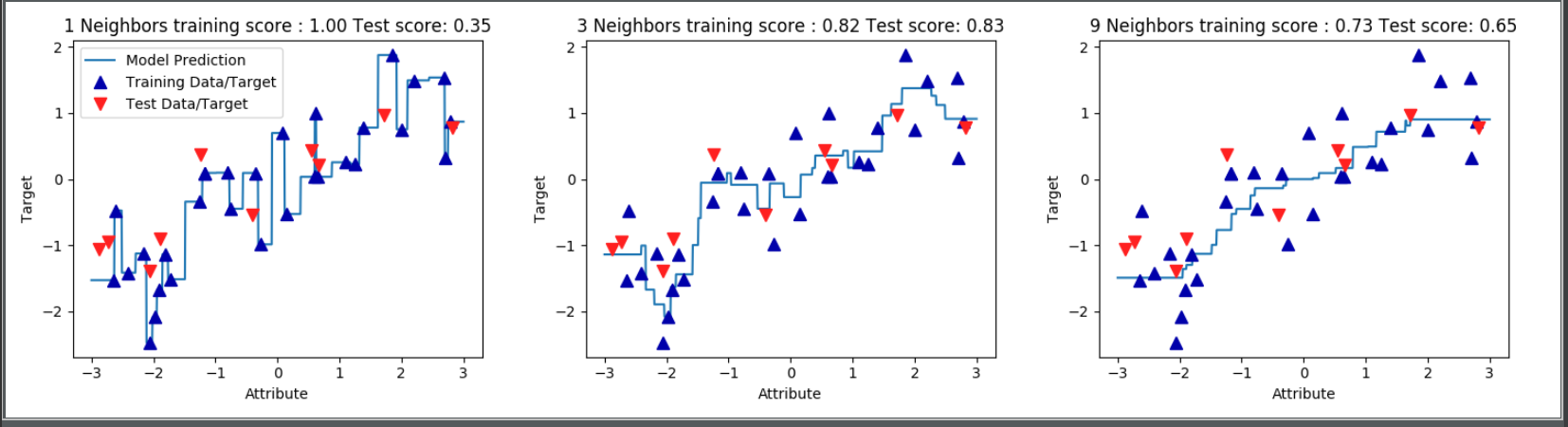
* 이웃의 수가 적을 수록 모델은 복잡해진다.
- 훈련 데이터 예측 정확도 상승, 테스트 데이터 정확도 하락
- 극단적인 경우, 최근접 이웃의 수가 하나일 경우 훈련 데이터 예측률은 100%라 할 수 있지만 테스트 데이터에 대한 예측률은 가장 저조하다.
* 이웃의 수가 많을 수록 모델은 단순해진다
- 훈련 데이터 정확도 하락, 테스트 데이터 정확도 상승
- 극단적인 경우, 훈련 데이터 전체 개수를 이웃의 수로 지정하는 경우 모든 테스트 데이터에 대한 예측은 동일할 것이다.
따라서, 너무 복잡하지도 단순하지도 않은 모델을 세우는 것이 최선의 방법이라 할 수 있다.
다시 말해 이 경우도 과대적합, 과소적합의 특징이 보여진다고 할 수 있다. (https://honeyteacs.tistory.com/20?category=688750 참조)


*K-최근접 이웃 회귀(KNN-Regression)
- KNeighborsRegressor 사용
- 보통 wave 데이터를 사용하며, k개 이웃 간의 평균이 예측됨
- 회귀 모델에서의 예측의 적합도는 R^2으로 표현되며 1은 완벽한 예측, 0은 훈련 세트의 출력값인 y_train의 평균으로만 예측하는 경우이며 예측과 타깃이 상반된 경우 음수로도 표현된다.