[Machine Learning] 머신러닝 알고리즘(Machine Learning Algorithm) 적용에 앞선 데이터 분석
데이터 셋(dataset)을 대상으로 머신러닝 알고리즘(지도 학습(Supervised Learning))을 적용하기에 앞서 다음 세 가지를 평가해야 한다.
(인공 지능(Artificial Intelligence),머신 러닝(Machine Learning),딥 러닝(Deep Learning) 이란?: https://honeyteacs.tistory.com/8)
1. 해당 데이터 셋이 가지고 있는 키 값들(keys)이 무엇인지
2. 해당 데이터 셋 중 어느 것들을 머신러닝 모델을 만드는데 사용할 training set으로 사용할 것이며, 어느 것들을 모델이 잘 작동하는지를 평가하는 test set으로 사용할 것인지
3. training set을 기반으로한 출력값(클래스)들이 training set의 특성들에 맞는 출력값 별 구분된 분포를 가지는지
위의 세 가지를 평가하기 위하여 프로젝트 시작에 앞서, 예시 어플리케이션을 만드는데에 사용하였던 iris 데이터 셋을 사용하였다.
(Django Rest Framework 로 Scikit-Learn(사이킷런) 학습 및 예측 어플리케이션 웹상에서 이용하기: https://honeyteacs.tistory.com/6)
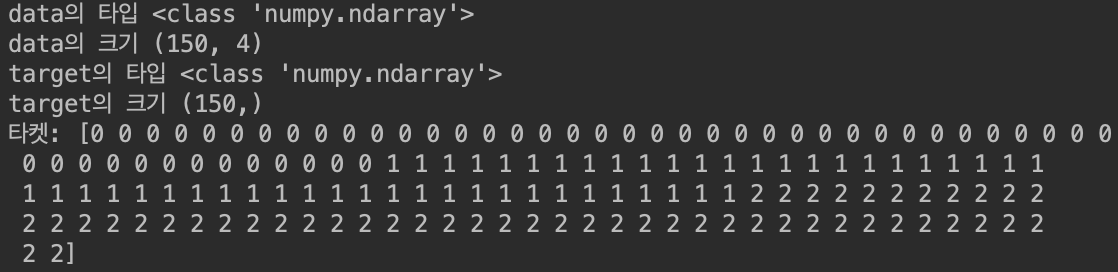
1. 데이터 셋이 가지고 있는 키 값들의 출력 및 각 키 값들이 가지고 있는 구체적인 내용 출력


2. train_test_split 함수를 이용한 training set 과 test set의 분리


3. X_train과 y_train을 토대로 한 출력값 분포도 분석

